ComfyUI: van prompt tot beeld en video
/
ComfyUI: van prompt tot beeld en video
Generatieve AI maakt het vandaag mogelijk om met één prompt beelden te genereren. Maar wie controle wil over hoe die beelden ontstaan, botst al snel op de limieten van standaard tools.
Met ComfyUI verandert dat volledig. In plaats van een “black box” werk je met een visuele, node-gebaseerde workflow waarin elke stap, van ruis tot eindbeeld, expliciet en manipuleerbaar is.
Dit geeft je niet alleen inzicht in het proces achter modellen zoals Stable Diffusion, maar ook de mogelijkheid om je resultaten doelgericht te sturen en te reproduceren.
Binnen het AI Lab passen we deze aanpak ook concreet toe in projecten zoals PSY-AID, waar gecontroleerde en reproduceerbare workflows essentieel zijn.
In deze blogpost ontdek je hoe ComfyUI werkt: van kerncomponenten zoals KSampler, CLIP en VAE, tot het bouwen van herhaalbare workflows en het kiezen van het juiste model voor jouw use case.

Main section
Kerngegevens
/
ComfyUI draait volledig lokaal (als je dat wil)
/
Node-gebaseerde workflows
/
Premade workflows versnellen je eerste projecten
ComfyUI uitgelegd: node-based workflows voor lokale AI-beeldgeneratie
Wat zijn node-based workflows?
In ComfyUI werk je niet met één enkele prompt en een “generate”-knop, maar met een visuele keten van stappen. Elke node voert een specifieke taak uit en geeft zijn output door aan de volgende stap.
Een workflow bestaat dus uit:
- input, zoals een tekstprompt of een afbeelding
- verwerking, zoals encoding, sampling en denoising
- output, het uiteindelijke beeld
Samen vormen deze nodes een gerichte graaf die het volledige generatieproces zichtbaar maakt.
Het verschil met klassieke tools is fundamenteel: je genereert niet zomaar een afbeelding, je bouwt een proces dat je kan begrijpen, aanpassen en hergebruiken. Dat maakt workflows niet alleen krachtig, maar ook reproduceerbaar.
Kerncomponenten van ComfyUI
Om controle te krijgen over je output, is het belangrijk te begrijpen hoe de kerncomponenten van ComfyUI samenwerken binnen een workflow.
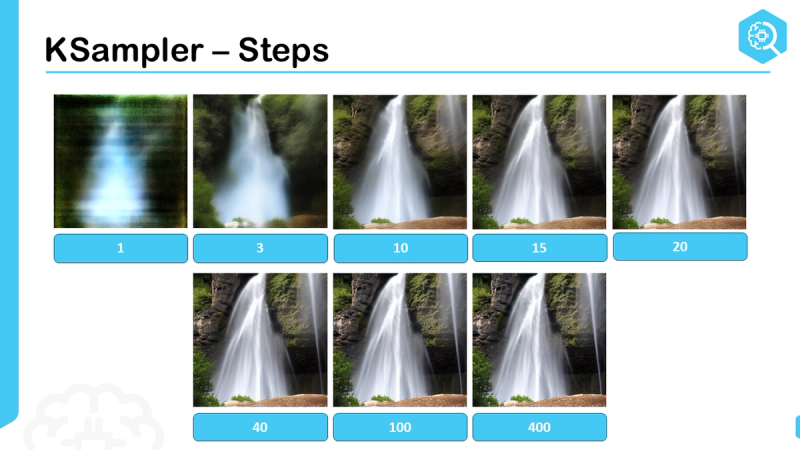
KSampler
Hier gebeurt de eigenlijke generatie. Willekeurige ruis wordt stap voor stap omgezet naar een latente representatie van een beeld. Parameters zoals het aantal stappen en CFG bepalen hoeveel detail er ontstaat en hoe strikt het model je prompt volgt.
CLIP Text Encoder
Deze component vertaalt je prompt naar vectoren die het model kan interpreteren. Kleine verschillen in formulering kunnen hier grote impact hebben, wat verklaart waarom prompt engineering zo’n grote rol speelt.
VAE Decoder
De output van het model is eerst een latente representatie. De VAE zet deze om naar pixels en maakt het beeld zichtbaar. Dit is de laatste stap waarin het resultaat vorm krijgt zoals wij het zien.
Samen bepalen deze componenten niet alleen wat je genereert, maar ook hoe voorspelbaar en consistent je resultaten zijn.
Kies het juiste model
De keuze van het model bepaalt vaak meer dan je prompt. In ComfyUI kan je verschillende modellen combineren en testen binnen dezelfde workflow.
- Stable Diffusion (SD1.x / SD2.x): snel en stabiel, ideaal om workflows op te bouwen en te testen
- SDXL / SD3.5: hogere kwaliteit en betere composities, maar zwaarder en trager
- FLUX-modellen: experimenteel en stijlgericht, minder voorspelbaar
- Fine-tuned modellen: essentieel voor consistente output binnen een specifieke stijl of domein
Door bewust een model te kiezen, stuur je niet alleen de kwaliteit van je output, maar ook het gedrag van je volledige workflow.
Alternatieven voor ComfyUI
Er bestaan verschillende tools voor AI-beeldgeneratie, elk met een andere focus:
- AUTOMATIC1111: snel starten, veel community support, maar beperkte controle
- Fooocus: laagdrempelig en eenvoudig, weinig configuratie nodig
- InvokeAI: hybride aanpak met lokale en cloud workflows
Voor snelle resultaten zijn deze tools vaak voldoende. Maar zodra je controle, inzicht en reproduceerbaarheid nodig hebt, kom je vanzelf uit bij ComfyUI.
Praktische tips
- Start met bestaande workflows en analyseer hoe ze opgebouwd zijn
- Pas één parameter tegelijk aan om te begrijpen wat er verandert
- Experimenteer met CFG en aantal stappen, meer is niet altijd beter
- Gebruik visualisaties van de latent space om inzicht te krijgen in het proces
Wie ComfyUI gebruikt zonder te begrijpen wat er gebeurt, mist het grootste voordeel van het systeem.

Videogeneratie met ComfyUI
Ook hebben we met ComfyUI de mogelijkheid om videomateriaal te genereren. Binnen het PSY-AID project maken we hier concreet gebruik van.
Binnen PSY-AID kwam er vanuit het ziekenhuis Maria-Middelares de vraag om een digitale persona op te bouwen op basis van bestaand beeld- en audiomateriaal. Het doel is om via tekstinput automatisch een video te genereren waarin deze persona spreekt en acties uitvoert.
Hiervoor experimenteren we met het open-source model LTX2.3 van Lightricks. Als input geven we een startafbeelding mee, samen met de tekst die uitgesproken moet worden.
Voor langere video’s splitsen we de generatie op in segmenten om het VRAM-gebruik te beperken. De laatste frame van elk segment wordt gebruikt als startframe voor het volgende, zodat continuïteit behouden blijft.
Er zijn verschillende workflows mogelijk:
- Tekst → video
- Afbeelding → video
- Afbeelding + audio → video
Voor PSY-AID gebruiken we de laatste workflow. Hierbij combineren we een afbeelding met extern gegenereerde audio. Het model zorgt voor animatie en lipsync, waarbij de mondbewegingen afgestemd worden op de audio.
Bottom section
Praktische toepassingen
Datasetcreatie voor vision-language modellen (VLMs)
Met ComfyUI kun je dezelfde workflow hergebruiken om honderden afbeeldingen te genereren met consistente stijl, compositie en labels. Dit levert direct bruikbare datasets voor training of finetuning van modellen zoals CLIP of multimodale LLMs, terwijl je volledige controle houdt over kleur, objectplaatsing en resolutie.
Visuele simulaties voor fysieke AI (robots)
Voor robots die visuele input nodig hebben, maken node-based workflows het mogelijk complexe scènes reproduceerbaar te simuleren. Door één node aan te passen, kun je snel scenario’s variëren en de robot testen met realistische visuele feedback, wat iteratief experimenteren efficiënt maakt.
Contributors
Authors
/
Thomas Dewitte, Intern
/
Jens Eeckhout, AI & XR researcher
Want to know more about our team?
Visit the team page