Verbeteren van LLM-nauwkeurigheid met Retrieval-Augmented Generation (RAG)
/
Verbeteren van LLM-nauwkeurigheid met Retrieval-Augmented Generation (RAG)
BijAI Labwe nemen momenteel deel aan een Europees project genaamdArt-IEmaar wat is Art-IE precies?
Art-IE is een Europese initiatief gericht opkleine bedrijven helpen innoveren met AIHet project bestaat uit drie hoofdgroepen:
1.Toegepaste AI Lab
2.AI Robotica Lab
3.Federated Learning Lab
Elke groep heeft zijn eigen expertisegebied.Howest AI Lab maakt deel uit van het Toegepaste AI Labwaar we ons richten op AI-toepassingen voormobiele apparaten, VR-headsets en meer.
Een van onze belangrijkste onderzoeksgebieden isRetrieval-Augmented Generation (RAG)—ervoor zorgen dat AI nauwkeurige, betrouwbare antwoorden geeft zonder te hallucineren of valse informatie te genereren.

Main section
Kerngegevens
/
Rommel erin is rommel eruit
/
Ophalen is cruciaal voor nauwkeurigheid
/
Correctieve RAG valideert documentrelevantie
RAG
RAGRetrieval-Augmented Generatieen het bestaat uit drie hoofdcomponenten:
1.Ophalen – De Juiste Gegevens Vinden
2.Augmentatie – Het Verbeteren van de Invoer
3.Generatie – Het creëren van het definitieve antwoord
In dit bericht zullen we ons richten op deophaalprocesen verken tweeRAG-implementatiesin detail.
Maar laten we eerst de verschillende RAG-stappen uiteenzetten.
1. Ophalen – De Juiste Gegevens Vinden
De eerste en waarschijnlijk meest cruciale stap isophalenHier neemt het systeem de vraag van de gebruiker en zoekt naar relevante informatie in een database. Als deze stap mislukt, wordt de rest van het proces zinloos.
Waarom is retrieval zo belangrijk?
Want als we de juiste gegevens niet ophalen, maakt het niet uit hoe goed we het in de volgende stappen verfijnen of verwerken - de uiteindelijke output zal nog steeds onjuist zijn. Dit wordt vaak in de IT samengevat met de zin:"Vuilnis erin, vuilnis eruit."
Stel je voor dat een gebruiker vraagt:Wat zijn afbeeldingsinvoegen?
Als de ophaalstap faalt en het systeem documenten ophaalt die alleen tekstembeddings bespreken, zal de AI een misleidend of onjuist antwoord genereren - omdat het nooit de juiste informatie heeft ontvangen in de eerste plaats.
Goede invoer (relevante documenten over afbeeldingsinbeddingen) → Correct antwoord
Slechte invoer (niet-gerelateerde of ontbrekende gegevens) → Onjuiste of vage reactie
Dit is waarom hoogwaardige retrieval cruciaal is; als de AI niet de juiste gegevens heeft, kan geen enkele hoeveelheid verwerking de output verbeteren.
Vanwege dit zijn er verschillende retrievaltechnieken, waarvan we er 2 (Corrective RAG en RAG-Fusion) verder in het artikel zullen verkennen.
2. Augmentatie – Verfijnen van de Invoer
Zodra we de relevante gegevens hebben opgehaald, is de volgende stapversterkenhet door het op te nemen in de prompt van de AI. Deze stap is cruciaal omdat het helpt om te vormenhoehet model genereert zijn reactie.
Door de prompt zorgvuldig te structureren, kunnen weleid de output van het modelom een specifiek formaat of stijl te volgen. Bovendien kunnen we beperkingen opleggen die ervoor zorgen dat de reactie strikt is gebaseerd op de verstrekte documenten—dit is bijzonder nuttig voorgevoelige of zeer nauwkeurige onderwerpen.
Technieken zoalsprompt engineeringspeelt een sleutelrol in dit proces, maar we zullen die later in meer detail verkennen.
3. Generatie – Het produceren van het uiteindelijke antwoord
In de laatste stap maakt het systeem gebruik van ofwelopen-sourceofgesloten bronAI-modellen om een reactie te genereren op basis van de opgehaalde en aangevulde gegevens.
De keuze van het model is cruciaal, aangezien sommigegesloten-source modellen voldoen mogelijk niet volledig aan de GDPR of andere ethische regelgevingHet selecteren van het juiste model zorgt ervoor dat de output in overeenstemming is met zowel technische vereisten als juridische overwegingen.
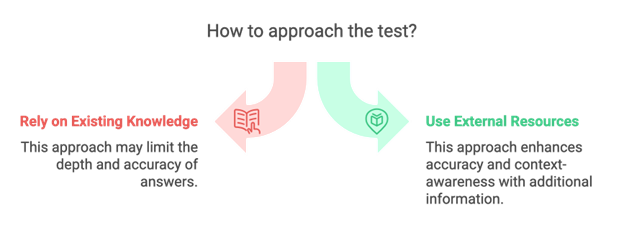
Een Eenvoudige Analogie
Stel je twee mensen voor die dezelfde test afleggen.
•Persoon Asteunt alleen op wat ze tot nu toe hebben geleerd.
•Persoon Bheeft dezelfde kennis maar heeft ook toegang tot eenbibliotheek vol informatieen, nog beter, eenkaartom snel precies te vinden wat ze nodig hebben.
RAG werkt alsPersoon Bcombinerenbestaande kennis met externe gegevensophalingom meer nauwkeurige en contextbewuste antwoorden te genereren.
Nu we weten wat RAG is en hoe het werkt, kunnen we dieper ingaan op elk onderdeel.
Wat gebeurt er vóór RAG?
Een cruciaal aspect dat we nog niet hebben besproken iswat er gebeurt voordat het RAG-proces begintHoe verkrijgen we de gegevens? Wat voor soort gegevens kunnen we gebruiken?
Dit staat bekend als devoorverwerkingsfase. Voor onze toepassingen kan de data afkomstig zijn vantekstbestanden, PDF's, afbeeldingen en meer.
We zullen in dit artikel niet te diep op dit onderwerp ingaan, aangezien het een aparte discussie verdient. Om wat context te geven, bestaat de preprocessingfase uit:
1.Gegevens verzamelen
2.Voorverwerking(e.g., chunking, tekst schoonmaken, enz.)
3.Inbedden en opslaan van gegevens in een vector database
Met deze achtergrond in gedachten, laten we doorgaan naar de eerste stap van het RAG-proces:Ophalen.
Implementatie van RAG-Fusion
Een van de methoden die we hebben geïmplementeerd isRAG-Fusionmaar wat is RAG-Fusion precies?
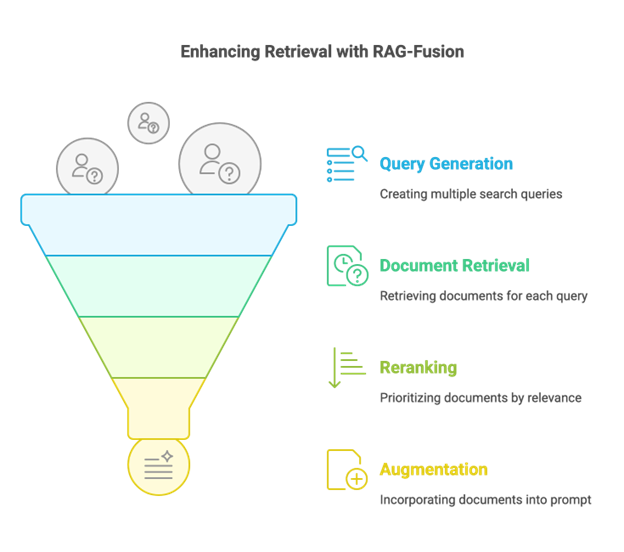
RAG-Fusion verbetert het retrievalproces doormeerdere zoekopdrachten genereren, documenten voor elk ophalen, en danherordeningze voor optimale relevantie. Het werkt in drie belangrijke stappen:
1. Querygeneratie
In plaats van te vertrouwen op een enkele gebruikersquery, dequery generatorcreëert meerdere gerelateerde zoekopdrachten. Dit helpt om extra context te bieden en vergroot de kans om de meest relevante documenten te vinden.
Bijvoorbeeld, als een gebruiker de eenvoudige vraag stelt:
Wat zijn afbeeldingsinbeddingen?
De querygenerator kan dit uitbreiden naar:
1.Hoe werken afbeeldingsinbeddingen in computer vision?
2.Wat zijn de toepassingen van afbeeldingsinbeddingen in machine learning?
3.Hoe kan ik afbeeldingsembeddings maken met Python-bibliotheken?
Door de reikwijdte van de query te verbreden, kan het systeem meer ophalen.omvattende en contextuele informatiewat leidt tot duidelijkere, meer informatieve antwoorden die voorbeelden en toepassingen in de echte wereld bevatten.
2. Document Retrieval & Reranking
Voor elke gegenereerde query haalt het systeem relevante documenten op. Aangezien meerdere queries overlappende of anders gerangschikte resultaten kunnen opleveren, gebruiken we eenherordening algoritmeom de meest relevante informatie prioriteit te geven.
Een veelgebruikte methode voor herordening isReciprocal Rank Fusion (RRF), dat een score toekent op basis van de rangpositie:
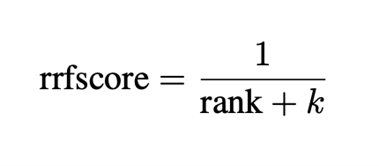
3. Augmentatie & Antwoordgeneratie
Zodra de documenten opnieuw zijn gerangschikt, verplaatsen de meest relevante naar deaugmentatiestap, waar ze in de prompt zijn opgenomen. Ten slotte genereert het AI-model een goed geïnformeerd antwoord.
Door RAG-Fusion te gebruiken, kunnen weverhoog de opzoeknauwkeurigheidenverbeter de algehele kwaliteit van gegenereerde antwoorden.
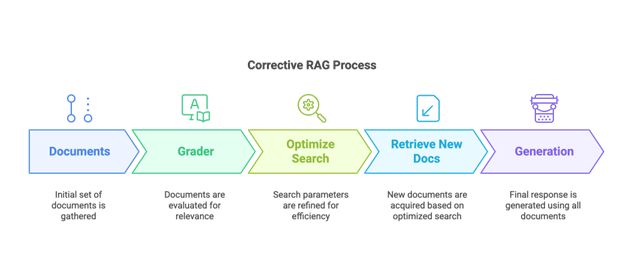
Implementatie van Correctieve RAG
Na RAG-Fusion hebben we ook geïntegreerdCorrectieve RAGmaar wat is Corrective RAG precies?
Zoals de naam al aangeeft,Correctieve RAG heeft als doel de nauwkeurigheid van het retrievalproces te verbeteren.door de relevantie van elk opgehaald document te verifiëren voordat het wordt gebruikt in de generatie stap.
Hoe werkt Correctieve RAG?
Correctieve RAG verbetert het retrievalproces doorelke document evaluerenom te zorgen dat het aansluit bij de vraag van de gebruiker. Dit wordt gedaan door eengrote taalmodel (LLM)om de relevantie van het document te beoordelen.
Een benadering omvat eensemantische relevantiecontrole, waar de LLM naar kijktsleutelwoorden of gerelateerde betekenissenbinnen het document. De volgende prompt kan worden gebruikt:
U bent een beoordelaar die de relevantie van een opgehaald document beoordeelt ten opzichte van een gebruikersvraag.
Als het document trefwoord(en) of semantische betekenis bevat die verband houden met de vraag, beoordeel het dan als relevant.
Geef een binaire score 'ja' of 'nee' om aan te geven of het document relevant is voor de vraag.
Gebruikersvraag:{query}
Opgehaald Document:{context}
Relevant:”
Deze methode zorgt ervoor dat alleen documenten met betekenisvolle context gerelateerd aan de vraag worden overwogen.
Harde Corrigerende Prompts
Voor bepaalde toepassingen, eenstriktere validatieis nodig—vooral wanneer het antwoord expliciet aanwezig moet zijn in de opgehaalde documenten. Dit is nuttig in scenario's zoalstechnische documentatie zoekopdrachten, waar de reactie direct moet verwijzen naarfoutcodes of exacte oplossingen.
In deze gevallen kunnen we eenhard correctieve promptdat een strengere eis afdwingt:
"U bent een beoordelaar die de relevantie van een opgehaald document beoordeelt ten opzichte van een gebruikersvraag."
ja
Gebruikersvraag:{query}
Opgehaald Document:{context}
Antwoord:”
Door toepassingCorrectieve RAG, kunnen we aanzienlijkverminder irrelevante of misleidende antwoorden, ervoor zorgend dat de AI biedtnauwkeurige, feitelijke antwoorden.
Wat gebeurt er na de beoordelaar?
Zodra de beoordelaar de opgehaalde documenten heeft geëvalueerd, is de volgende stap omoptimaliseer de zoekopdrachten gebruikweb crawlers of scrapersom meer relevante of nauwkeurige bronnen te vinden.
Dit kan gedaan worden metaangepaste codeofbestaande open-source of gesloten-source oplossingen. Deze stap vereist echter zorgvuldige behandeling, aangezien niet alle online informatie betrouwbaar is. Zoekmachines en websites bevattenmisleidende, verouderde of irrelevante inhouddus zijn aanvullende waarborgen noodzakelijk.
Belangrijke overwegingen voor webscraping
Om de kwaliteit van opgehaalde documenten te verbeteren, nemen we verschillende voorzorgsmaatregelen:
1.Beperk bronnen– Definieer een set vangoedgekeurde URL'som ervoor te zorgen dat de scraper alleen informatie ophaalt vanvertrouwdwebsites.
2.Beperk diepte en reikwijdte– Beperk de scraper tot detop X resultatenen voorkomen dat het te diep in irrelevante pagina's kruipt.
3.Onderhoud query-uitlijning– Zorg ervoor dat dezoekopdracht blijft trouw aan de oorspronkelijke intentie van de gebruikerom off-topic resultaten te vermijden.
4.Respecteer de websitebeleid– Altijdcontroleer en voldoe aan de robots.txt van een websitebestand envermijd het scrapen van sites die het verbiedenDit is cruciaal, aangezien ongeautoriseerd scrapen steeds meer wordt beperkt.
Eindantwoordgeneratie
Zodra de gescrapete documenten aan de context zijn toegevoegd, kan het systeem eendefinitief, goed geïnformeerd antwoord. Om transparantie te waarborgen, wijinclusief altijd de URL's van de gebruikte bronnenzodat de gebruiker precies weet waar de informatie vandaan komt.
Augmentatie – Structureren van de Invoer
Nu we hebbende documenten opgehaaldengecontroleerd hun nauwkeurigheid, kunnen we doorgaan naar deAugmentatiefase.
Waarom is augmentatie belangrijk?
Augmentatie isevenzo cruciaal als ophalenomdat het bepaalthoe de LLM de opgehaalde gegevens verwerkt en integreert. Zelfs met de juiste informatie moeten we nog steedsleid het modeldoor het doel duidelijk te definiëren en instructies te geven over hoe de gegevens effectief te gebruiken.
De prompt moet zorgvuldig zijnop maat gemaakt voor de specifieke gebruikszaakBijvoorbeeld, als het systeem is ontworpen voortechnische RAG gericht op foutcodes, de prompt kan er als volgt uitzien:
Context die je moet gebruiken:{context}
Query:{query}
Instructies:
Op basis van de gegeven context, analyseer de relevante foutcodes voor de gebruikersvraag en genereer een gestructureerd antwoord dat helpt bij het oplossen van het probleem. Zorg ervoor dat het antwoord het volgende bevat:
•Defoutcode
•Hetbeschrijving
•Mogelijke oorzaken
•Aanbevolen oplossingen
Prioriteer de meest relevante en kritische informatie om de gebruiker efficiënt te helpen.
Als de context de feiten of informatie met betrekking tot de vraag van de gebruiker niet bevat, geef dan terug:
“Deze informatie is niet beschikbaar.”
Antwoord:
Door de prompt op deze manier te structureren, zorgen we ervoor dat deLLM begrijpt het doelen genereertnauwkeurige, goed gestructureerde antwoorden.
Zoals eerder vermeld, kan augmentatie eencomplex en uitgebreid proces, maar dit artikel richt zich op het bieden van eenalgemeen overzicht van RAGmet een nadruk optwee verschillende opvragingmethoden.
Laatste stap: Generatie
De laatste stap,Generatie, is misschien wel de eenvoudigste van de drie. Hier nemen we deverruimde prompten stuur het naar onzeLLM naar keuze, dat vervolgens een reactie genereert die aan de gebruiker wordt geleverd.
Bronnen:
Bottom section
Afsluiten
We hebben nu de verkenning van dedrie belangrijke pijlers van RAGmet een bijzondere focus optwee geavanceerde opzoektechniekenDit sluit onze overzicht van RAG en de rol ervan in het verbeteren van AI-gestuurde zoek- en responsystemen af.
Als je geïnteresseerd bent om dieper in te gaan op specifieke aspecten van RAG, laat het ons weten - we kunnen het in een toekomstig artikel behandelen!
Contributors
Authors
/
Tim Bleuzé, Intern
/
Jens Eeckhout, AI & XR researcher
Want to know more about our team?
Visit the team page