Generative AI op je eigen data: finetuning met LoRA
/
Generative AI op je eigen data: finetuning met LoRA
Generative AI-modellen openen heel wat deuren voor organisaties die slimmer met informatie willen omgaan. Denk aan systemen die interne rapporten genereren, documenten samenvatten of vragen beantwoorden in een bedrijfsspecifieke stijl. De meest uitdagende stap is het vertalen van die algemene AI-kracht naar een context waarin je eigen data centraal staat.
In het ecosysteem rond taalmodellen bestaan daarvoor drie grote routes.
De figuur hiernaast positioneert ze duidelijk. Prompt Engineering is de meest laagdrempelige aanpak: je ontwerpt gerichte instructies en stuurt die naar het model. Dit al dan niet met je bedrijfsspecifieke data er aan toegevoegd. Retrieval-Augmented Generation koppelt een externe knowledge base aan een LLM zodat het kan antwoorden op basis van opgehaalde context. En via Fine-Tuning wordt het model zelf hertraind om structureel beter te presteren binnen jouw domein.
In deze blogpost focussen we op die laatste techniek: finetuning. We bespreken wat finetuning inhoudt, wanneer je dit het best inzet en hoe moderne technieken zoals LoRA en QLoRA deze stap praktisch haalbaar maken.

Main section
Kerngegevens
/
Finetunen als alternatief voor RAG en prompting
/
Grote modellen, grote uitdagingen
/
Finetunen met beperktere hardware: (Q)LoRA
/
Voorkom catastrophic forgetting
Finetuning als fundament voor gespecialiseerde AI-modellen.
Van basismodel naar aangepast model.
Finetuning is het proces waarbij een bestaand taalmodel verder wordt getraind met een kleinere, taakgerichte dataset. De figuur hieronder toont dit als een eenvoudige flow: je start met een model dat geleerd heeft uit een grote algemene corpus. Door het te trainen op je eigen data wordt het gedrag verfijnd. Zo ontstaat een finaal model dat beter past bij concrete real-world toepassingen.
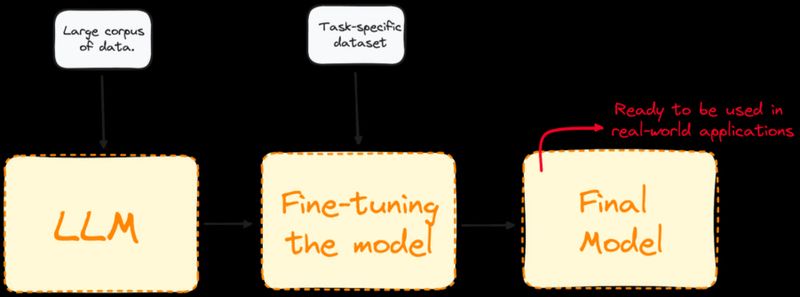
Finetuning zorgt ervoor dat kennis en taakgedrag niet telkens opnieuw via de prompt moeten worden meegegeven, maar rechtstreeks in het model aanwezig zijn. Dit verlaagt de kostprijs.
Wanneer Gebruik Je Finetuning?
Finetuning is niet altijd nodig. Voor veel use-cases volstaat een goed doordachte prompt of een RAG-architectuur. Je kiest voor finetuning wanneer de noden specifieker en structureler worden.
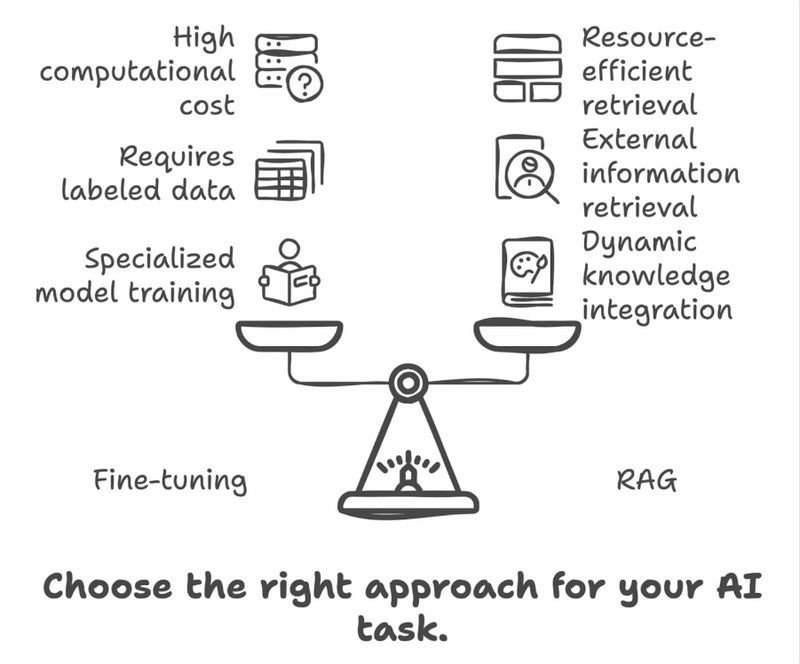
De figuur hierboven illustreert dit. Typische scenario’s om finetuning te gebruiken zijn:
- Het model moet diepgaande expertise krijgen in een specifiek domein. Dit op grotere schaal dan gewoon RAG.
- Je wilt een model toepassen voor een nieuwe (programmeer)taal.
- Je beschikt over een nieuwe dataset met een grote hoeveelheid documenten die relevant blijven.
- Inference-snelheid is belangrijk
- De informatie is te omvangrijk of te gespecialiseerd voor RAG.
Finetuning is aangewezen van zodra je op een schaal werkt die nog groter is dan die waarvoor je enkel RAG zou gebruiken. De nadelen van finetuning zijn echter de kost om het model te trainen, de grote nood aan data en het risico op hallucineren en vergeten van de originele info waar het model mee getraind is (catastrophic forgetting).
Overzicht van Finetuning Methoden
Binnen finetuning bestaan verschillende technische benaderingen. We bespreken er twee.
Full Finetuning
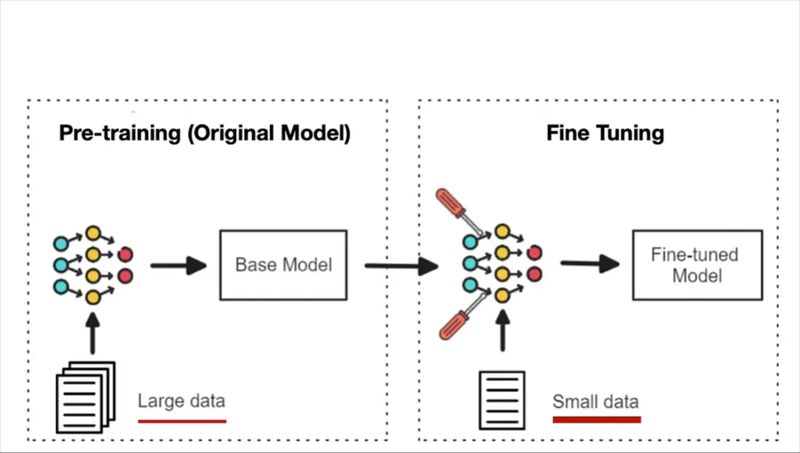
Bovenstaande figuur toont het principe van full finetuning. Hierbij worden alle parameters van het basismodel aangepast. Dit geeft volledige vrijheid, maar vraagt zware hardware en veel trainingsdata. Het resultaat kan zeer performant zijn voor één taak, maar minder geschikt voor modulaire omgevingen.
Parameter Efficient Finetuning (PEFT)
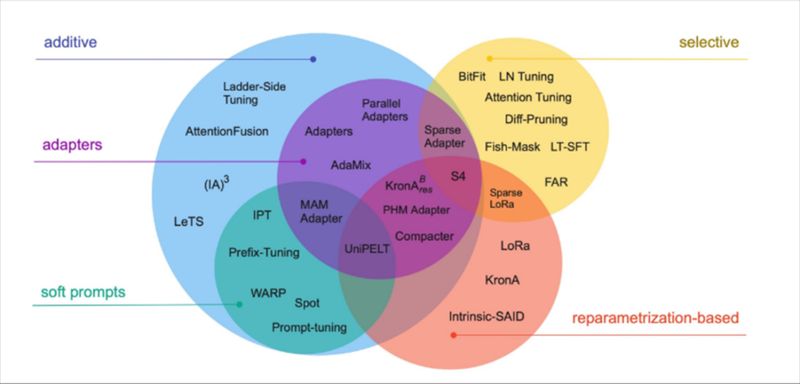
PEFT is een hele familie van methoden die je kan gebruiken om op een efficiënte manier je model te hertrainen. Het PEFT-landschap is heel breed. Het centrale idee is dat je niet het volledige model hertraint, maar kleine uitbreidingen toevoegt.
PEFT biedt daardoor:
- Beperkte(re) geheugenvereisten
- sneller trainen
- minder risico op overfitting en catastrophic forgetting
- Beperktere nood aan data
- gebruik van adapters naast het basismodel
Binnen dit landschap is LoRA de meest gebruikte en meest productieklare techniek.
Hoe werkt LoRA?
Wanneer je een taalmodel klassiek finetunet, moet tijdens training voor élke parameter ook een gradient worden bijgehouden. Bij grote LLM’s leidt dat tot een enorme nood aan GPU-geheugen (bijvoorbeeld 17 Gigabyte benodigd geheugen voor een 7 miljard parameter model). Veel van die parameters bevatten echter overlappende of redundante informatie. LoRA speelt precies daarop in.
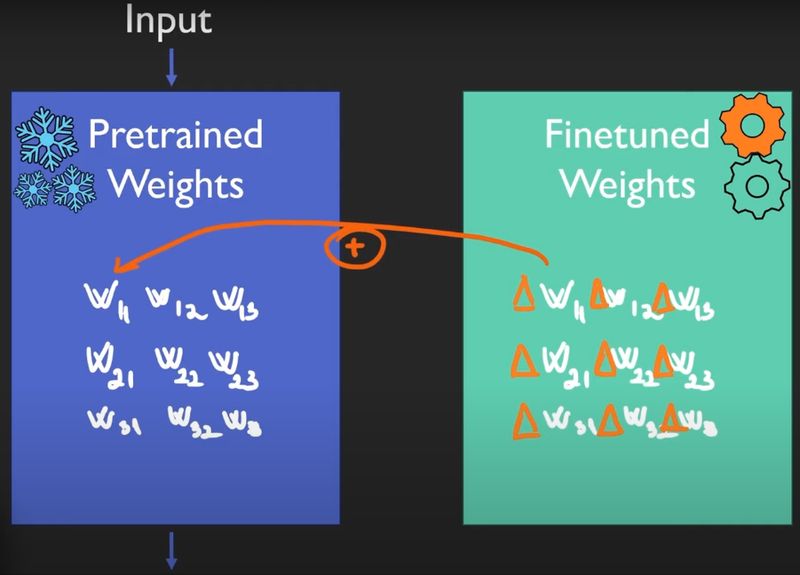
LoRA (Low-Rank Adaptation) vertrekt van het idee dat je het oorspronkelijke, vooraf getrainde model niet hoeft te wijzigen. In plaats daarvan worden de bestaande gewichten volledig bevroren. Bovenop bepaalde lagen van het model worden kleine extra matrices toegevoegd die enkel de noodzakelijke correcties leren.
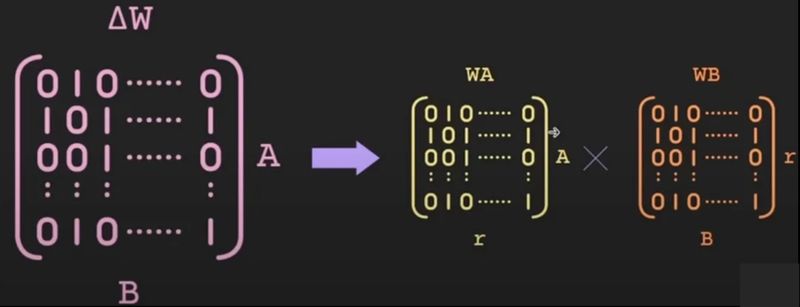
Concreet wordt niet de volledige weightmatrix hertraind, maar een compacte “delta-matrix” die wordt opgesplitst in twee veel kleinere matrices met lage rang. Tijdens inference berekent het model eerst het antwoord met de originele gewichten. De LoRA-layers voegen daar vervolgens een beperkte, gerichte aanpassing aan toe.
Hierdoor ontstaat een model dat gespecialiseerd gedrag vertoont, terwijl het basismodel generiek en stabiel blijft.
Belangrijkste voordelen:
- Slechts een fractie van de parameters is trainbaar
- Training wordt mogelijk op lichtere hardware
- Adapters zijn klein en snel op te slaan
- Meerdere LoRA-adapters kunnen naast elkaar bestaan
- Snelle omschakeling tussen taken
- Geen catastrophic forgetting
LoRA maakt finetuning dus modulair: je kunt één krachtig basismodel combineren met verschillende taakgerichte uitbreidingen.
Wat is QLoRA?
QLoRA bouwt verder op LoRA, maar voegt een extra optimalisatiestap toe: quantization van het basismodel.
Bij QLoRA wordt het vooraf getrainde taalmodel eerst geladen in een sterk gecomprimeerde representatie, meestal 4-bit. Dat betekent dat elke parameter veel minder geheugen inneemt dan in 16- of 32-bit precisie. Op dit gequantiseerde model worden daarna LoRA-layers geplaatst die wél in hogere precisie worden getraind.
De combinatie werkt als volgt:
- Download en laad een gequantiseerd basismodel
- Bevriest alle oorspronkelijke gewichten
- Train alleen de compacte LoRA-adapters
- Gebruik het gefinetunede resultaat voor snelle inference
Doordat het basismodel zo licht is, kan QLoRA ook worden toegepast op modellen met tientallen miljarden parameters zonder nood aan professionele GPU-clusters. De inference blijft performant omdat de LoRA-layers precies leren welke informatie cruciaal is voor de specifieke taak.
QLoRA biedt daardoor:
- Drastisch lagere hardwarevereisten
- Snellere en goedkopere training
- Mogelijkheid om zeer grote modellen te gebruiken
- Minder energieverbruik
- Productiewaardige prestaties
Bottom section
Combineer technieken voor het beste resultaat
Finetuning levert een gespecialiseerd model op, maar staat zelden alleen. In de praktijk wil je zowel diepe domeinkennis als actuele informatie en controle over gedrag.
De figuur in bijlage over “Combine fine-tuning and RAG” toont dat elke techniek zijn sterktes heeft. Daarom combineer je ze best als volgt:
- Prompting wordt gebruikt om de interactiestijl van je agent te sturen. Hier voeg je eventueel een beperkte hoeveelheid eigen data aan toe om de kostprijs niet te veel op te drijven.
- RAG levert actuele, dynamische context uit je interne documenten. Zo is het mogelijk om zonder te hertrainen, snel nieuwe data toe te voegen.
- Finetuning met LoRA/QLoRA integreert stabiele domeinexpertise rechtstreeks in het model. Dit doe je om de zoveel tijd eens om je model om te leren gaan met een grote hoeveelheid statische nieuwe data.
Door een gefinetuned basismodel in te zetten binnen een pipeline met prompting en retrieval krijg je:
- kortere prompts
- minder hallucinaties
- snellere inference
- maximale flexibiliteit bij nieuwe data
Zo bouw je generative AI-systemen die zowel performant als onderhoudbaar zijn.
Deze blogpost is mogelijk gemaakt door het Interreg Vlaanderen-Nederland project Art-IE.