LLM4News
/
LLM4News
Nieuwsconsumptie verandert snel. Steeds vaker krijgen gebruikers hun informatie via korte antwoorden in zoekmachines of via gepersonaliseerde nieuwsstromen, zonder nog door te klikken naar een volledig artikel. Deze evolutie naar een zogenaamde answer economy legt extra druk op nieuwsredacties: niet alleen om correcte informatie te brengen, maar ook om kwalitatieve en betrouwbare antwoorden te leveren in nieuwe, vaak geautomatiseerde contexten.
Tegelijk tonen verschillende studies van onder andere de EBU, BBC en NewsGuard aan dat de grote taalmodellen die vandaag al door miljoenen gebruikers worden ingezet om nieuws en informatie te raadplegen, nog onvoldoende betrouwbaar zijn om journalistieke content correct en genuanceerd over te brengen.
In het onderzoeksproject LLM4News hebben we de voorbije vijf maanden onderzocht hoe deze modellen presteren in het Vlaams, en welke oplossingen mogelijk zijn om hun redactionele kwaliteit en betrouwbaarheid te versterken.

Main section
Kerngegevens
/
Geen vervanging voor de redactie
/
Taalmodellen zijn geen journalisten
/
RAG is een noodzakelijke filter
Wat we binnen het LLM4NEWS project hebben bekeken
Limitaties van taalmodellen
Betrouwbaarheid is een kernwaarde in journalistiek. Toch tonen recente evaluaties aan dat huidige taalmodellen daar nog niet aan voldoen. In een onderzoek van de BBC bevatte bijna één op de vijf gegenereerde antwoorden feitelijke fouten. Gelijkaardige conclusies werden getrokken in studies van de EBU en NewsGuard.
Deze tekortkomingen zijn geen toeval, maar het gevolg van een aantal structurele eigenschappen van taalmodellen. Hieronder lichten we de belangrijkste toe, met oog voor hun impact op nieuwsproductie.
Knowledge cutoff
Taalmodellen leren niet voortdurend bij. Ze beschikken over een vaste kennisbasis die stopt op het moment van hun training.
Concreet betekent dit dat een model dat werd getraind tot december 2025 geen kennis heeft van gebeurtenissen in januari 2026, tenzij die expliciet worden aangeleverd.
Grote spelers zoals OpenAI en Google proberen dit te omzeilen door modellen toegang te geven tot online bronnen. Die informatie kan echter niet automatisch worden geverifieerd volgens journalistieke standaarden.
Geen diepgaande journalistieke kennis
Taalmodellen zijn ontworpen voor algemeen gebruik. Ze zijn niet getraind om te werken volgens journalistieke principes zoals bronkritiek, nieuwswaardering of redactionele afwegingen.
Via prompts kan een model wel gevraagd worden om “te schrijven als een journalist”, maar dit blijft een oppervlakkige sturing en geen structurele oplossing.
Inherente cultuur
Nieuws is contextueel en cultureel bepaald. De manier waarop een gebeurtenis wordt gebracht in de Verenigde Staten verschilt van de toon en nuance die verwacht wordt in België of Vlaanderen.
Tijdens ons onderzoek merkten we dat Engelstalige modellen, vaak getraind op overwegend Amerikaans materiaal, minder goed aansluiten bij Vlaamse gevoeligheden. Modellen zoals ChocoLlama, gebaseerd op Llama 2 maar verder getraind op Vlaamse teksten, presteren hier merkbaar beter.
Antwoorddrang
Taalmodellen zijn ontworpen om altijd een antwoord te geven. Ook wanneer hun kennis onvolledig of onzeker is, zullen ze toch een ogenschijnlijk overtuigend antwoord formuleren.
In een journalistieke context kan dit leiden tot fouten, ongefundeerde aannames of het ontbreken van noodzakelijke nuance.
Ons onderzoek
In het project LLM4News onderzochten we in welke mate taalmodellen geschikt zijn voor gebruik in een journalistieke context, en of technieken zoals RetrievalAugmented Generation (RAG) hun kwaliteit kunnen verbeteren.
RAG laat toe om een AI-model te laten werken met bijkomende, gecontroleerde informatiebronnen — vergelijkbaar met hoe een journalist bronnen raadpleegt vóór publicatie.
Om dit te testen, vergeleken we vier AI-configuraties:
- NL-Chat: een Nederlandstalig model zonder extra bronnen
- NL-RAG: hetzelfde model, aangevuld met eigen kennisbronnen
- ENG-Chat: een Engelstalig model zonder extra bronnen
- ENG-RAG: het Engelstalige model met RAG
Voor de Engelstalige configuraties gebruikten we een model van Mistral. Voor de Nederlandstalige configuraties werkten we met ChocoLlama, een model dat bijkomend is getraind op Vlaamse teksten.
Testopzet
We stelden een set van 121 inhoudelijke vragen op, gespreid over zeven inhoudelijke domeinen, gebaseerd op een dataset die we ter beschikking kregen van Roularta.
Elke AI-configuratie genereerde een antwoord op deze vragen. Die antwoorden werden vervolgens geëvalueerd via een beoordelingsformulier dat we verspreidden binnen het werkveld, met aandacht voor criteria die essentieel zijn in journalistiek, zoals:
- Feitelijke nauwkeurigheid
- Onpartijdigheid
- Feiten onderscheiden van meningen
- Voldoende context
- Taalkundige kwaliteit
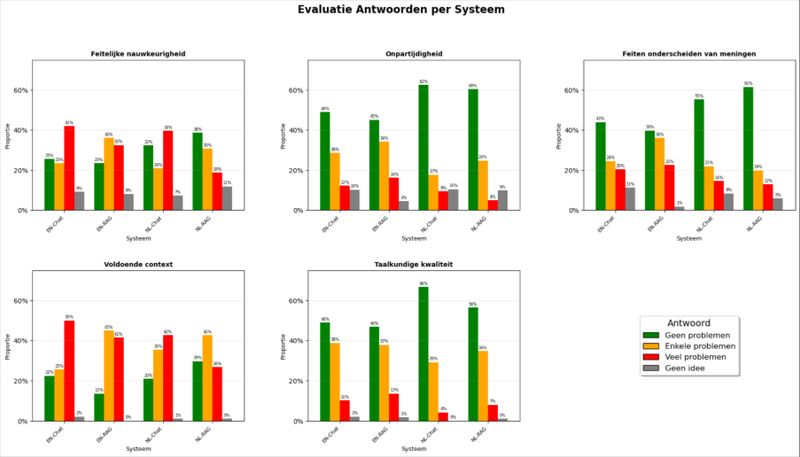
Belangrijkste bevindingen
Op basis van deze evaluaties kunnen we een aantal duidelijke conclusies trekken:
- Feitelijke correctheid en volledigheid blijven de grootste pijnpunten bij alle geteste modellen.
- RAG vermindert het risico op zware fouten of misleidende antwoorden, maar voorkomt geen kleinere onnauwkeurigheden.
- Nederlandstalige configuraties scoren over het algemeen beter op taal, nuance, onpartijdigheid en volledigheid.
- NL-RAG presteerde globaal het best, met uitzondering van taalcorrectheid, waar NL-Chat licht beter scoorde.
- De Nederlandstalige systemen kwamen consistenter en genuanceerder over dan hun Engelstalige tegenhangers.
Deze resultaten tonen aan dat zowel taalcontext als toegang tot betrouwbare bronnen een belangrijke rol spelen in de inzetbaarheid van AI binnen nieuwsredacties.
Aanbevelingen
De resultaten van LLM4News tonen aan dat taalmodellen kansen bieden voor de mediasector, maar alleen wanneer ze doordacht en verantwoordelijk worden ingezet. Op basis van ons onderzoek formuleren we de volgende aanbevelingen.
1. Kies voor een hybride aanpak
Taalmodellen mogen redactionele processen ondersteunen, maar geen volledig autonome rol opnemen.
- Laat door AI gegenereerde content altijd nakijken door redactionele medewerkers.
- Gebruik AI als assistent, niet als eindverantwoordelijke.
2. Voorzie duidelijke governance en afspraken
Een duidelijke structuur rond AI-gebruik voorkomt risico’s en wildgroei.
- Richt een interne AI-werkgroep op met zowel redactionele als technische profielen.
- Ontwikkel een helder AI-charter met richtlijnen voor gebruik.
- Duidelijke afspraken verkleinen het risico op shadow AI, waarbij medewerkers ongecontroleerde tools inzetten buiten het zicht van de organisatie.
3. Evalueer vóór en tijdens implementatie
Kwaliteitscontrole mag geen eenmalige oefening zijn.
- Implementeer evaluatie-instrumenten om outputs systematisch te testen.
- Maak gebruik van bestaande tools zoals Civics (voor vragen van publiek belang) en Shades (om schadelijke stereotypen te detecteren) voordat een AI-toepassing live gaat.
4. Werk met eigen, betrouwbare kennisbronnen
Gebruik het eigen archief als gecontroleerde kennisdatabank.
- Zet Retrieval Augmented Generation (RAG) in om modellen te laten werken met gevalideerde content.
- Vermeld expliciet welke bronnen werden gebruikt en verwijs gebruikers door naar de originele artikels.
5. Wees transparant naar het publiek
Duidelijke communicatie versterkt vertrouwen.
- Voorzie een “about this”-pagina waarin je uitlegt hoe het systeem werkt en welke rol AI speelt.
- Schep realistische verwachtingen: maak duidelijk dat het systeem geen alwetende kennisbron is.
6. Positioneer AI als ontdekkingstool
Presenteer AI-toepassingen niet als vervanging van journalistiek, maar als toegangspoort.
- Positioneer de tool als een geavanceerde zoek- en ontdekkingstool die gebruikers helpt om sneller relevante, geverifieerde artikels te vinden.
- Stimuleer verdieping in plaats van oppervlakkige antwoorden.
7. Ontwikkel met het doelpubliek in gedachten
Gebruiksvriendelijkheid bepaalt mee het succes.
- Ontwikkel AI-oplossingen op maat van het eindpubliek.
- Voorzie voorbeeldvragen of suggesties om gebruikers te begeleiden in hun interactie met het systeem.
Bottom section
Verdere interesse?
Wil je dieper ingaan op de resultaten van dit onderzoek of bekijken wat dit kan betekenen voor jouw mediaorganisatie?
Je kan het volledig onderzoeksrapport raadplegen of starten met de one-pager voor een beknopt overzicht.
Heb je vragen, interesse in ons vervolgonderzoek of wil je verkennen hoe deze inzichten toepasbaar zijn binnen jouw redactie of organisatie?
Neem gerust contact op met Ingmar Proot , projectleider van LLM4News, via Ingmar.PROOT@howest.be