Workshop Private Agentic AI
/
Workshop Private Agentic AI
In het kader van het Art-IE project - gefinancierd door Interreg Vlaanderen Nederland - organiseerde Howest AI Lab een workshop “Private Agentic AI”. We gingen dieper in op de volgende topics:
- Hoe LLMs natuurlijke taal begrijpen
- RAG & AI agents
- LLM frameworks & guardrailing
- Hardware en softwarebenodigdheden voor infrastructuur
De focus lag op een privacy-first aanpak waarbij we alles zelf hosten op onze nieuwe krachtige AI server. Deze blogpost bespreekt kort de inhoud van de workshop en de gebruikte tools. Midden november volgt een minder technische workshop die voor iedereen toegankelijk is (meer info onderaan).
Schrijf je alvast in via de forms

Main section
Kerngegevens
/
Agents automatiseren jouw workflow
/
LLM guardrails beschermen jouw chatbot
/
Kubernetes & NVIDIA voor AI servers
Inhoud van de workshop
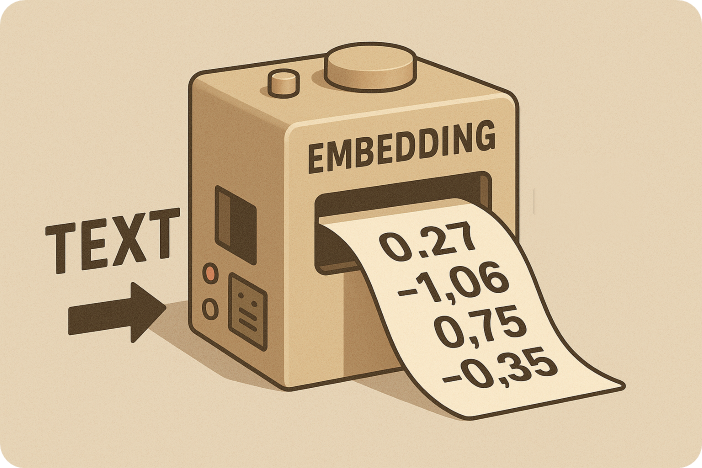
Embedding modellen
Een computer ziet in tekst geen betekenis zoals een mens, maar kan wel aan hoge snelheden rekenen met getallen. Een embedder is een AI-model dat tekst omzet in een reeks getallen die we een vector heten. Deze vectorrepresentaties hebben twee belangrijke eigenschappen:
- Ze bevatten informatie die iets zegt over de relaties tussen woorden, men kan a.d.h.v. vectoren bijvoorbeeld aantonen dat “brunch” qua betekenis ergens tussenin “ontbijt” en “lunch” ligt. Ook kennen embedders aan synoniemen gelijkaardige getallen toe.
- We kunnen er de sterkte van de gelijkenis tussen twee woorden mee uitdrukken. Hier zitten wiskundige berekeningen achter zoals de “cosine similarity”.
Er zijn heel wat open-source embedding modellen beschikbaar op HuggingFace en Ollama. Tijdens de workshop gingen wij aan de slag met EmbeddingGemma, een recente ontwikkeling van Google.
RAG
LLMs zijn qua kennis gelimiteerd tot hun training dataset. Ook kunnen ze hallucineren en zijn ze soms bevooroordeeld.
Retrieval Augmented Generation ofwel RAG is een implementatie van LLMs waarbij we onze eigen kennisdatabank kunnen bevragen. De chatbot kan dus bronnen raadplegen en vermelden in zijn antwoord. Dit vermijd grotendeels de problemen met LLMs, maar ook RAG kan fouten maken.
Zo’n kennisdatabank bestaat typisch uit je bedrijfsdocumenten, of documentatie van machines in een industriële context. Deze zijn vaak vertrouwelijk of bevatten sensitieve persoonsgegevens.
Om de privacy te garanderen kunnen we de volledige RAG pipeline ook zelf lokaal hosten. Er bestaan open-source “all-in-one” platformen zoals RAGFlow die men met Docker kan draaien op elke computer. Tijdens de workshop hebben we RAG eens manueel uitgewerkt met LangChain in Python.
Als privacy geen prioriteit is bestaan er ook cloud-alternatieven zoals NotebookLM van Google.
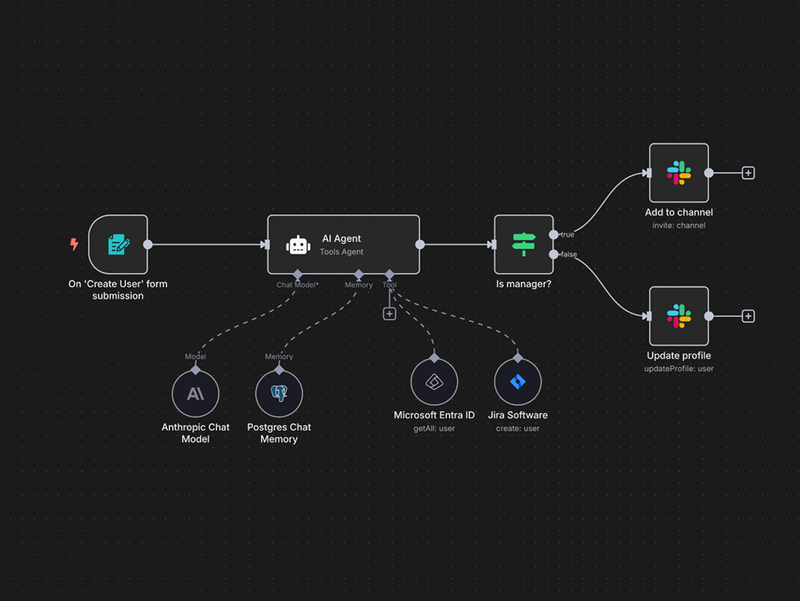
Agents
Een agent is een LLM die acties kan uitvoeren, dit zijn enkele voorbeelden:
- Een kennisdatabank bevragen (RAG)
- Het weerbericht ophalen
- Een mail versturen in jouw naam
- …
In de context van agents verwijzen we naar deze acties als “tools”. Om de LLM bewust te maken van de beschikbare tools, maken we gebruik van het MCP protocol.
Veel apps bieden tegenwoordig ook een MCP server aan, deze bevat de tools waarmee een LLM acties kan uitvoeren op die app. Een developer of platform zoals n8n kan hier gebruik van maken om een agent te bouwen. Tijdens de workshop hebben we onze eigen lokale MCP server opgezet met FastMCP in Python.
Guardrailing
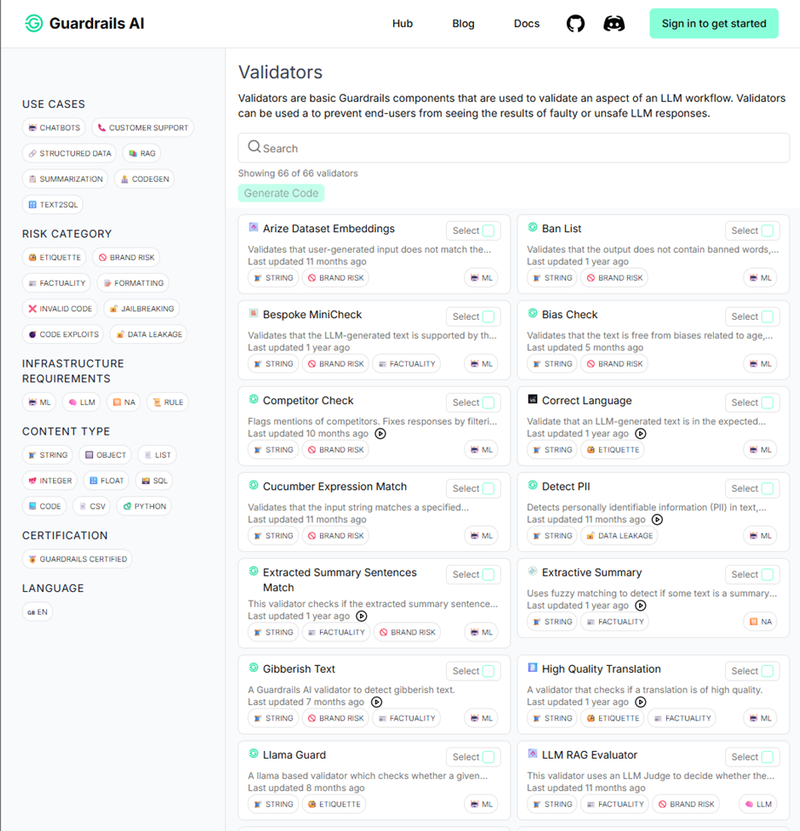
LLMs en agents zijn kwetsbaar voor kwaadaardige prompts (prompt injection of jailbreaking). Ook ongewenste outputs zoals scheldwoorden, persoonsgegevens of verkeerde talen kunnen problematisch zijn. Daarom zijn extra beveiligingen essentieel in productie-omgevingen.
Tijdens de workshop gebruikten we Guardrails AI, een Python library die voorgemaakte guardrails bevat. Je kan er gebruikersprompts en LLM-antwoorden mee pre- of postprocessen en controles op uitvoeren. Achterliggend gebruiken ze hier verschillende technieken voor, eentje daarvan is het gebruik van gefinetunede taalmodellen die gespecialiseerd zijn in guardrailing-taken (bv. Llama Guard 3). Nog een ander open-source alternatief is Granite Guardian van IBM.
Infrastructuur
Tijdens de workshop gingen we ook wat dieper in op de infrastructuurvereisten om AI applicaties te kunnen draaien. In vele gevallen heb je nood aan krachtige GPU’s van NVIDIA. Door middel van subsidies via het Interreg Vlaanderen-Nederland Art-IE project & een VLAIO infrastructuurcall heeft Howest een nieuwe AI server aangekocht met onderstaande specificaties:
- CPU: 2x Intel Xeon Platinum 8562Y+ (128 threads)
- GPU: 8x NVIDIA H200 SMX (141GB VRAM)
- RAM: 2TB DDR5
- Opslag: 2x Dell NVMe 7500 (3.84TB) + 5x Micron 9300 (3.5TB)
Belangrijk is dat er heel wat verborgen kosten bijkomen zoals stroom, licenties & software, support, …
Op vlak van software gebruiken wij Kubernetes in combinatie met Kubeflow. Dit is een open-source ecosysteem die goed integreert met de hardware & software van NVIDIA. Kubeflow bestaat in de eerste plaats uit een modulair centraal dashboard. Je kan er modules aan toevoegen om het aanmaken van Jupyter Notebooks, pipelines, model training, enzovoort mogelijk te maken en de resources ervan te beheren.

Bottom section
Volgende workshop
Wil je inspiratie opdoen over hoe je jouw werk kan automatiseren en optimaliseren met agents? Midden november organiseren we in het kader van het project AIUPD8 een vervolgworkshop waarbij we hands-on aan de slag gaan met agent platformen zoals n8n, Copilot, ChatGPT agents, Relevance AI en meer. Voor deze platformen heb je zelfs geen programmeerkennis meer nodig en is dus voor iedereen toegankelijk!
Bronnen
https://en.wikipedia.org/wiki/Cosine_similarity
https://huggingface.co/models?other=embeddings
https://ollama.com/search?c=embedding
https://developers.googleblog.com/en/introducing-embeddinggemma
https://modelcontextprotocol.io/docs/getting-started/intro
https://gofastmcp.com/getting-started/welcome
https://ollama.com/library/llama-guard3
https://www.ibm.com/architectures/product-guides/granite-guardian